EKS versus KOPs
Recently, I worked on an interesting project wherein we migrated from a KOPS to an EKS cluster. This led me to read up on Docker, Kubernetes, EKS, and more. We also merged a smaller project with this initiative, during which we migrated all non-production environment resources to a new AWS account—details of which are also covered in this blog.
928 words | Read Time: 4 Minutes, 13 Seconds
2025-03-01 14:36 +0000
Docker, Kubernetes, EKS, and More
Docker is primarily a containerisation platform that helps in packaging and shipping applications along with all their dependencies inside containers. It acts as a container runtime engine—responsible for running containers. While Docker initially used its own proprietary runtime, it later transitioned to a custom-built engine, containerd, which it eventually donated to the Cloud Native Computing Foundation (CNCF).
Kubernetes, often described as an orchestration tool for Docker, provides much more. It enables teams to create, manage, and deploy application containers across clusters. A cluster defines the context in which applications run, and Kubernetes allows the same application to run across multiple such contexts—given the appropriate configuration.
A Kubernetes cluster consists of two main components:
Control Plane – Manages the worker nodes and hosts the API server, scheduler, and networking components. It provides the front-end interface for interacting with pods and containers.
Data Plane – Comprises the worker nodes, which run pods (the smallest deployable units in Kubernetes). Each pod contains one or more tightly coupled containers. Nodes communicate with the control plane via kubelet, and each pod runs on a container runtime engine.
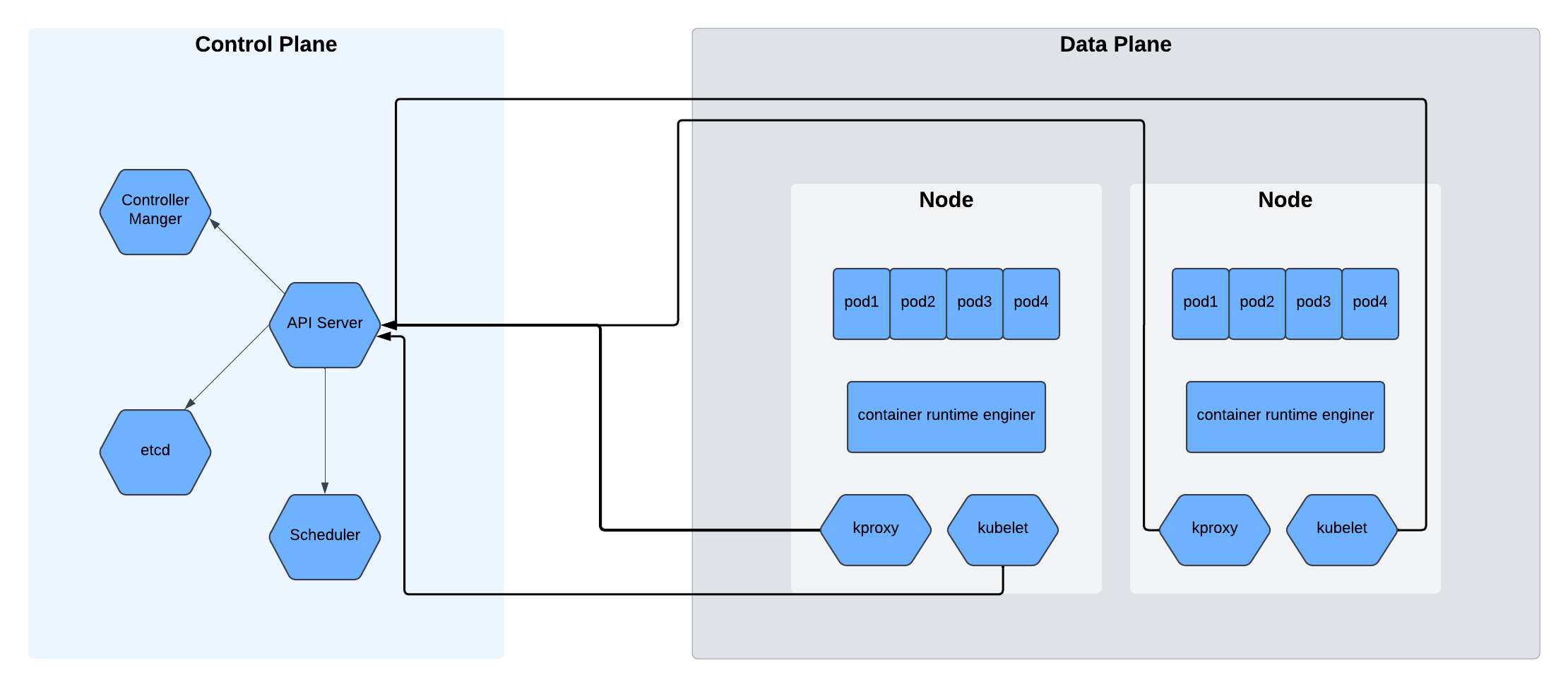
etcd is a fault-tolerant key-value store that maintains the configuration data for the cluster. kube-proxy handles networking and communication between services and pods. Docker remains one of the most widely used container runtimes in this ecosystem.
Running Kubernetes comes with its own complexities. Maintaining a master node and ensuring high availability of the control plane can be challenging. These concerns, along with the need for tighter integration with other AWS services, often lead teams to use Amazon EKS.
EKS is AWS’s managed Kubernetes service. It provisions and maintains the control plane on your behalf, including managing availability and automating failover to different availability zones in case of downtime.
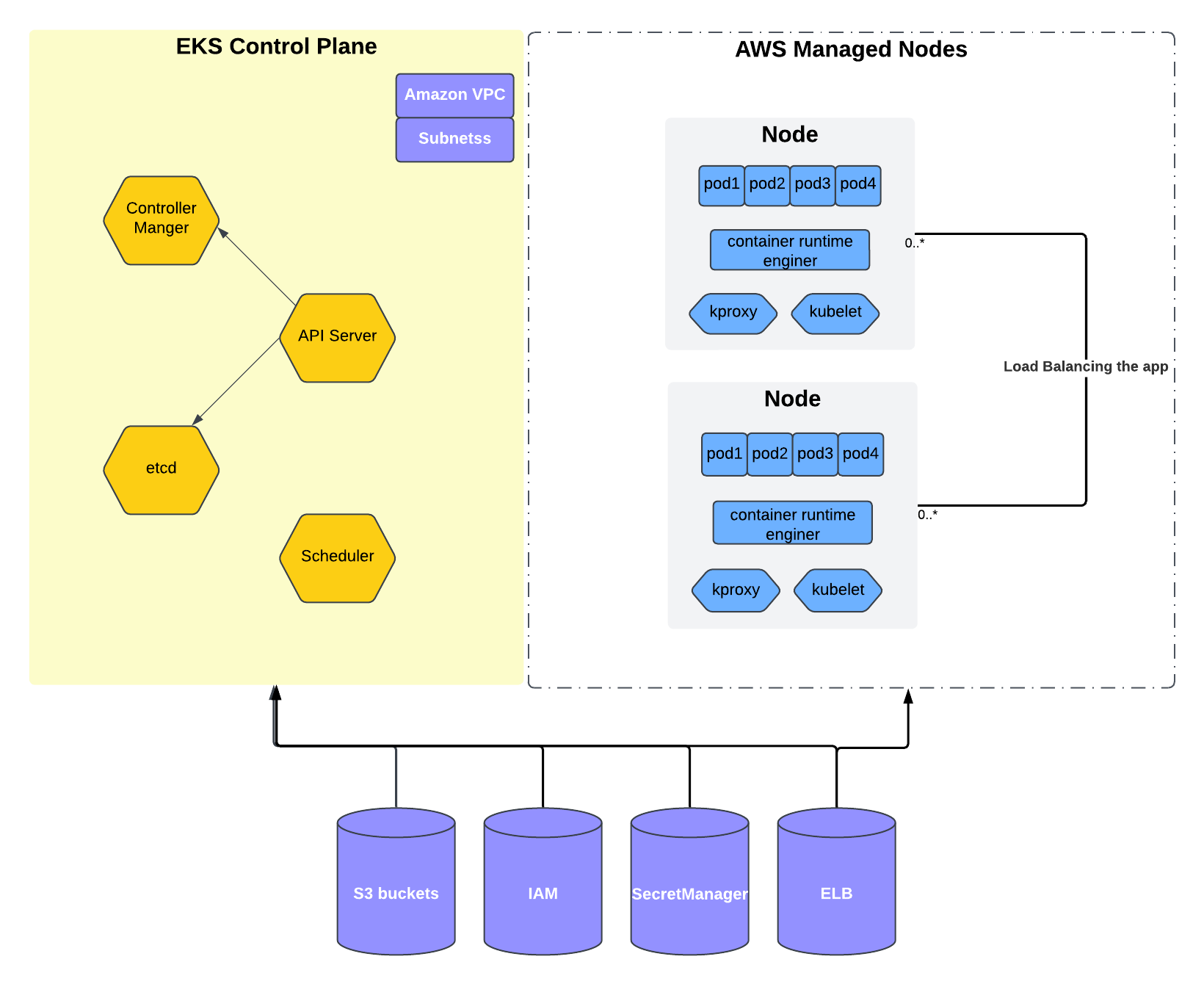
In the diagram, you can see the nodes labeled as “AWS Managed Nodes.” There are multiple approaches to provisioning worker nodes. One can manually create EC2 instances, install required dependencies, and configure services like kubelet and kube-proxy, but this setup requires additional effort. Instead, we chose to use AWS Managed Nodes, which automate much of this configuration through simple API calls. AWS handles installation, networking, and security best practices out of the box. Another alternative is AWS Fargate—a serverless option (which I’ll cover in a future post).
EKS Migration: How to go about it?
We performed the migration in a phased manner. All services were migrated gradually while the KOPS cluster remained operational. This allowed us to troubleshoot issues with minimal downtime, since the legacy cluster served as a fallback. We redirected traffic at the API Gateway level to maintain codebase consistency, which simplified the switch.
We followed AWS’s EKS setup guide to build the base infrastructure. The documentation offers detailed, step-by-step instructions.
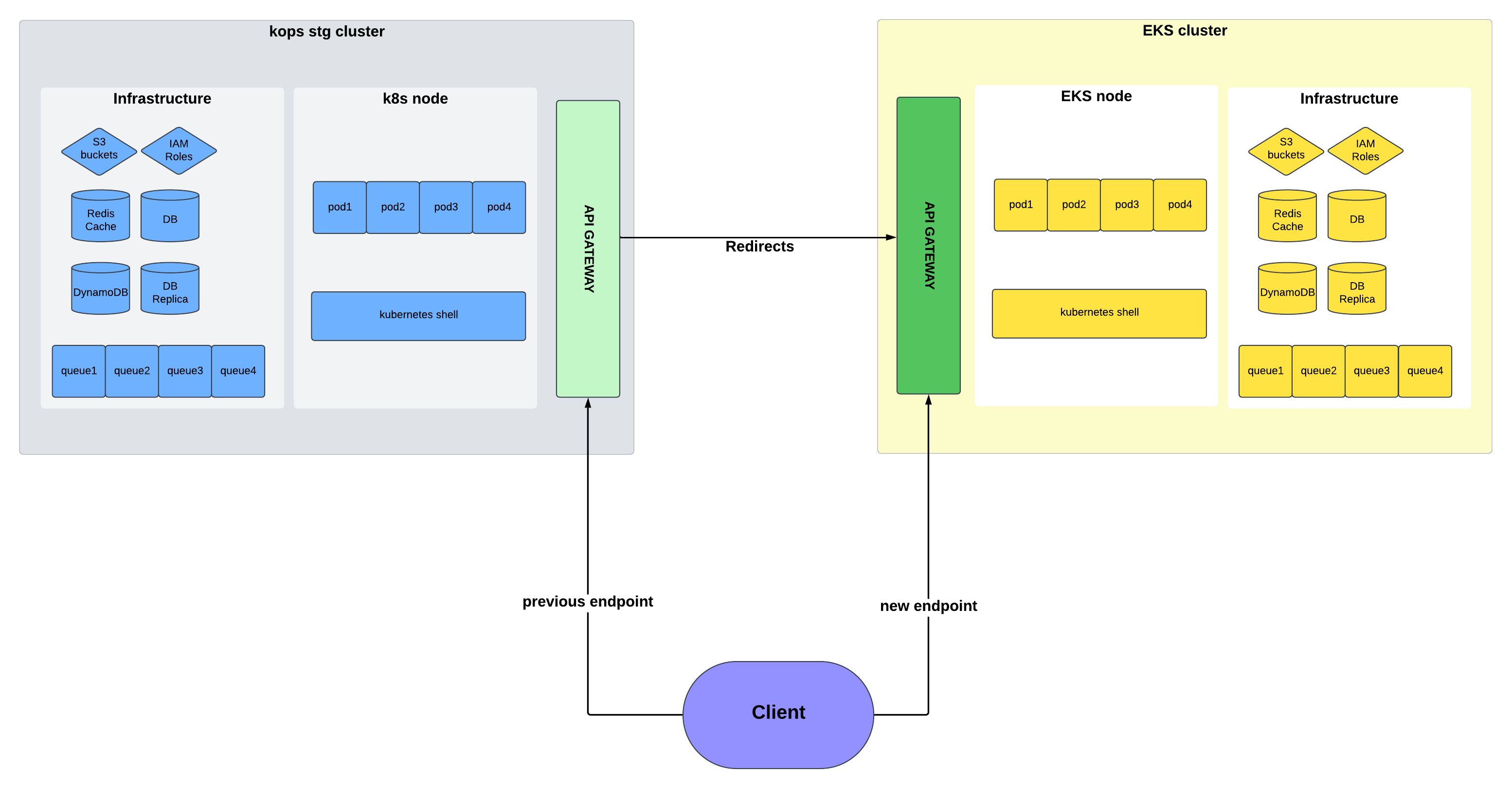
Once the foundation was in place, the rest of the migration was straightforward. We created new IAM roles, configured DNS records, and deployed services on the new cluster. Testing played a critical role—we validated endpoints, API behavior, APMs, services, databases, and monitoring metrics.
Despite careful planning, we encountered a few surprises. One involved POST requests returning a 301 Moved Permanently response instead of the expected body. These non-obvious issues are difficult to preempt, but we anticipated many others by consulting engineers outside our project. By asking them which tools and endpoints they relied on most, we could backtrack to ensure the related services were correctly configured on EKS.
Key components like the load balancer and VPCs were among the first to be replicated. The second layer included secrets, environment variables, and dependencies. No matter how thorough the testing, unexpected behaviors will emerge—being responsive and having good logs helped us adapt quickly.
AWS Account Migration
As seen in the architecture diagram, the old and new clusters resided in separate AWS accounts with distinct infrastructure—different S3 buckets, RDS databases, Shoryuken queues, etc. Unlike typical EKS migrations where the infrastructure layer stays intact, this effort also involved an AWS account migration.
For large codebases, isolating production and non-production environments into separate AWS accounts is considered best practice. In our case, we created a new directory and pointed all Terraform resources to the new account. We then cloned resources from the old account: DynamoDB tables, RDS/Aurora instances, IAM roles, Route53 entries, S3 buckets, Shoryuken queues, and supporting policies like DLQs.
We knew many services would have hidden dependencies tied to the AWS account. Our testing strategy had to account for broken environment variables, secrets, or roles with insufficient privileges. Occasionally, a service would still point to the old account. To manage this, we opened a dedicated channel for developers to flag any issues they encountered post-migration.
Our phased approach provided valuable feedback loops. Each environment—preview, staging, and production—gave us opportunities to catch issues before the final cutover.
This migration was truly a cross-team effort. For example, the DBA team helped with database and PgBouncer switchover, while the App-Arch team oversaw Shoryuken job transitions. Developers were actively involved, debugging early and staying aligned with the migration documentation we shared internally.
Challenges
Here are some of the challenges we faced—both technical and organizational—that might help future teams:
a) Technical Challenges
Understanding end-to-end flows across services had a steep learning curve
Setting up new dashboards, APMs, and observability pipelines
Anticipating and testing high-risk areas
Debugging issues required deep log analysis, sometimes even tailing logs at the container level
b) Non-Technical Challenges
Logging and tracking every change for transparency and feedback
Documenting the entire migration process clearly for all developers
Coordinating with cross-functional teams for team-specific resource migration
Ensuring availability and quick response times to unblock other developers